
Canonical Room Definitions: The Foundation Under Cross-OTA Comparability
Sources: OTA partner documentation (Booking.com Partner Hub room-name guidance, Expedia algorithm explainer / VLF, Google Hotel Center room-bundle definition), and OTALift product behavior verified against the codebase on 2026-05-10.
Key takeaways
A boutique hotel with 18 keys ends up with more room categories on Booking.com than on Google Hotels, with Expedia somewhere in the middle. The room counts on each surface refer to the same physical rooms, but the names and category boundaries almost never line up. Booking will list "Deluxe Double Room with Garden View" as a separate type from "Deluxe Double Room with Sea View"; Expedia may collapse them into "Deluxe Double Room" with a view as a sub-attribute; Google may show them as one room with two photos. The same physical room is three different SKUs in three different catalogs.
This naming chaos is not a bug in the OTAs. Each platform's content schema reflects how its search filters, sort logic, and price comparison engines work. Booking's room schema is documented in its Partner Hub Room Categories reference 1; Expedia's Visual Listing Framework specifies a five-level room hierarchy 2; Google Hotel Center's room types feed schema is published as part of the partner documentation 3. None of the three is wrong. They are deliberately different because the surfaces serve different traveler search behaviors.
The practitioner consequence: any analysis that compares "the same room across OTAs" needs a fourth definition that sits above all three. We call it the canonical room. It is the operator's source of truth for the rooms a guest can actually book at the property, and it is the join key that makes parity comparisons, photo coverage analysis, and inventory consistency possible. The step-by-step fix below walks the canonicalization workflow operators we observed used most often. The closing "How OTALift surfaces this" section describes how OTALift generates canonical rooms today, including what the engineering team is shipping to close audit-surfaced gaps.
Why it moves bookings
Three downstream decisions stall when canonical rooms are missing or wrong, and all three carry direct conversion impact.
Search-filter accuracy + Booking's own research backing. The room-type filter fires on every filtered search a traveler runs, which makes it one of the operator-controlled signals you can't afford to get wrong. A traveler searching Booking.com for "King bed" fires a ranking query that matches against Booking's standardized room-name taxonomy 1. Booking publishes its own claim about this directly in the Partner Hub guidance on naming: "Standard room and unit names help keep info clear and consistent for guests across our platform – and in all 43 languages we offer. Research shows that standard room and unit names also help generate more bookings" 1. The mechanism Booking enforces structurally: when an operator updates a room, they pick a Room type, then select a Room name from Booking's standard list, then optionally enter a Custom name that only they can see. Guests see only the standardized name, not the operator's internal label 1. Expedia and Google have analogous structures (Expedia's Offer Strength factor #1 is "Room availability and inventory" with explicit Content completeness as factor #3 2; Google's "room bundle" framework defines room types as physical-room + service-package combinations 3). When your "King Suite" lands as a "Suite" on Booking but a "Studio" on Expedia and a non-bundled room type on Google, three different ranking algorithms fire different filters against different buckets, and the cumulative conversion drag is proportional to how often each filter mismatch happens.
Parity comparisons that actually compare like rooms. Rate parity audits, the kind covered in Rate Parity Fundamentals, are useful only when the rooms being compared across OTAs are the same physical room. A property whose Booking "Deluxe Double" maps to Expedia's "Standard Double" will read as "$30 cheaper on Expedia" in a naive parity audit when in fact the Expedia rate is for a different room. Sophisticated parity tools build a room-mapping layer above the OTA feeds for exactly this reason. Without canonical rooms, the parity report is noise.
Photo coverage allocation. Every photo-strategy article in The Labs assumes you know which photos belong to which room. The Ideal Listing Photo Set prescribes per-room shot lists; the Bedroom Photo That Converts and Bathroom Photo Without the Motel Look describe what each room's anchor shot needs to look like. None of that prescription survives contact with reality if the property has six OTA-side rooms collapsed into one canonical room (because the LLM merged them aggressively) or two OTA-side rooms split across four canonical rooms (because the LLM hedged). The shot list either over-prescribes (operator photographs the same physical room four times under different names) or under-prescribes (operator misses a category entirely).
The OTAs' search and ranking algorithms do not see the property's "real" rooms. They see whatever was loaded into their feed, with whatever names and category attributes the operator (or their channel manager, or their content extraction) gave them. A property whose canonical room map is clean shows up in the right filters, prices like for like, and gets photographed completely. A property whose canonical map is missing or wrong loses bookings to causes that look operational (poor photos, wrong rate) but are actually upstream data hygiene.
What "great" looks like
Example 1 — Hostal Girona, Barcelona (standardized room-name compliance)
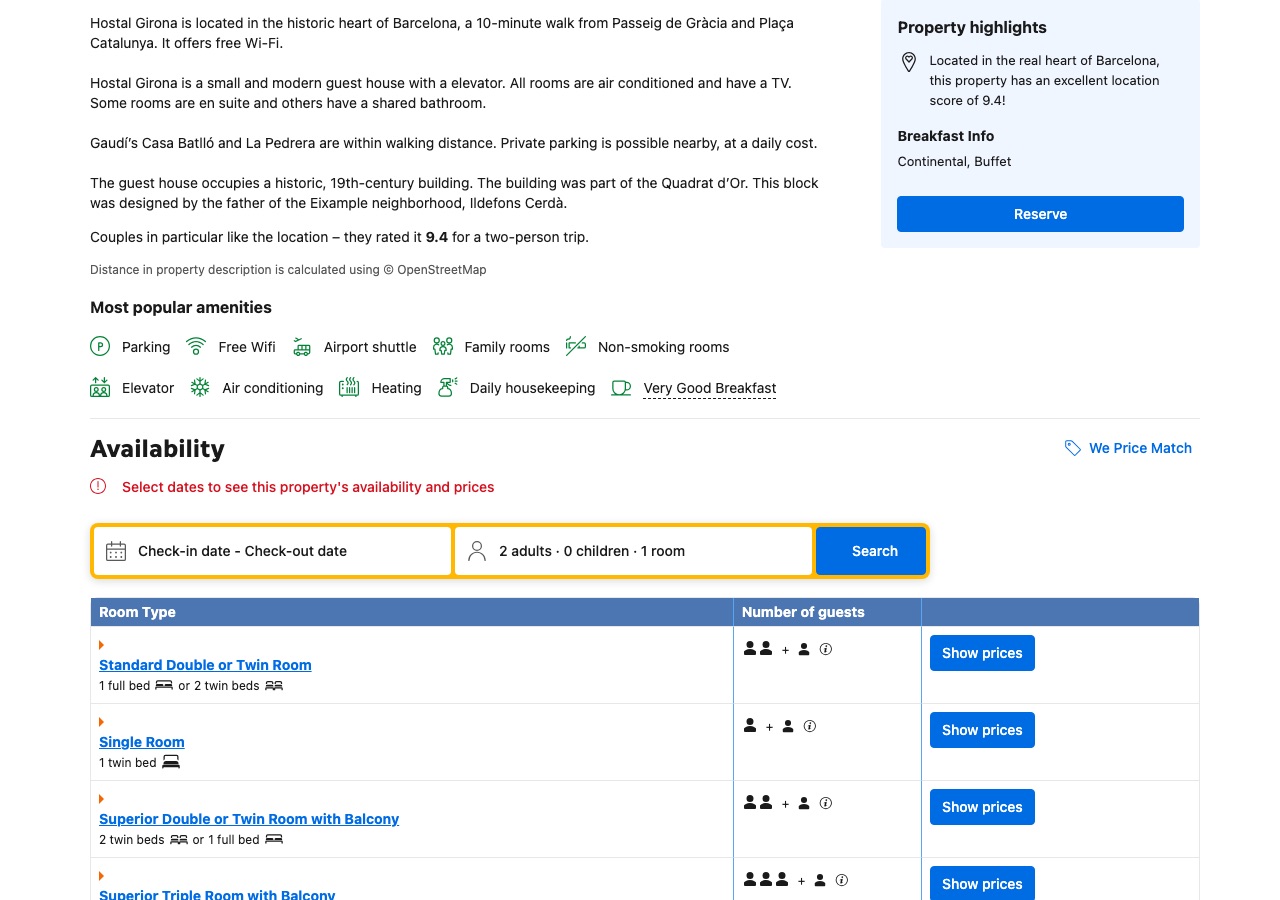
Why it works: Hostal Girona uses Booking's standardized room-name taxonomy verbatim. Every available room is labeled with one of Booking's controlled-vocabulary names rather than a free-text custom name. Bed configuration and max occupancy are consistent. This is exactly the operator-side discipline Booking's research-backed guidance recommends: "Standard room and unit names help keep info clear and consistent for guests across our platform – and in all 43 languages we offer. Research shows that standard room and unit names also help generate more bookings" 1. From an OTALift canonical-room perspective, each Booking-side row maps cleanly to one canonical room. No over-merge, no fragmentation.
The pattern across well-mapped properties:
- Each canonical room maps to exactly one room on each OTA where the room is listed. No "this canonical room covers two Booking rooms"; no "this canonical room is partially-mapped to an Expedia room with the rest going elsewhere".
- Canonical room names match the dominant guest mental model. A garden-view king is named "Garden King" if guests describe it that way in reviews, not "Superior Room Type B" because that's what the channel manager defaulted to.
- Bed configuration and max occupancy are consistent across OTAs, even when the OTA-side names differ. A canonical room marked "1 king + sleeps 2" should not show as a queen on one OTA and a king on another.
- Photos are routed to canonical rooms first, then split across OTA listings. The operator does not have a per-OTA photo workflow; they have a per-canonical-room workflow that fans out.
Common failure modes
The four patterns below are surfaced from OTALift RoomAlignment audits across the property base. Inline figures showing each pattern in the OTALift RoomAlignmentTable UI are deferred to the next revision, because they need to be captured from a property whose canonical map demonstrates the specific failure (under-merge / over-merge / drift / regenerate) and that requires curated property selection rather than synthetic examples.
1. The over-merge. A property with five physical room types (King, King Garden View, Queen, Queen Sea View, Family) ends up with two canonical rooms because the matching logic collapsed the view variants. Result: photo coverage is allocated to "King" without distinguishing garden vs sea, and the operator never realizes the sea-view room never gets its hero photo because the workflow says "King is done." Conversion on the higher-price sea-view room degrades silently.
2. The under-merge. The opposite. The property has one physical Deluxe King but it's listed under three different names across Booking ("Deluxe King", "Deluxe King Room", "Deluxe Double Bedroom") because the listings were created at different times by different staff. Canonicalization treats the three as separate canonical rooms. Photo coverage gets fragmented; the operator photographs the same room three times; rate parity reports flag spurious differences across the "three rooms".
3. The drift. Canonical rooms were defined a year ago, then the property added an accessible variant of the King and never re-mapped. The new room exists on Booking and Expedia but is not in the canonical set. It silently inherits the standard King's photos and recommendations, which under-serve the accessibility-focused traveler who arrived expecting the variant to be photographed and described.
4. The "regenerate to fix it" cycle. The operator notices the canonical map is wrong and clicks "Regenerate" hoping the LLM will do better this time. It might or might not. Without an operator-editing layer above the regeneration, the property is locked into whatever the LLM produces, with the only escape being to keep regenerating until the result happens to look right. This is a tooling failure, not an operator failure, and it is one of the gaps the "How OTALift surfaces this" section is honest about.
Step-by-step fix
The canonicalization workflow that we observed at well-mapped properties:
- Walk the property and list the rooms. Every room a guest can actually book, by bed config, max occupancy, view, and accessible variant. Square meters if you have them. Most boutiques land somewhere in the low single digits. This is your canonical room set.
- Name each canonical room from the guest perspective. "Garden King" beats "Superior Room Category B." If guests in your reviews describe the room as the "garden room" or the "sea-view king", use that language. Names that match how guests talk about the property convert better in OTA filters.
- Pull your current room set from each OTA. Booking → Extranet → Property → Rooms; Expedia → Partner Central → Rooms; Google → Hotel Center → Property → Room Types. Make a spreadsheet with one row per OTA-side room and one column per OTA.
- Map each OTA-side room to exactly one canonical room. A "Deluxe Double Garden View" on Booking and a "Garden Deluxe Room" on Expedia both map to your "Garden King" canonical row. If a single OTA has two rooms that should map to one canonical, that's a sign the OTA listing has fragmented (Failure Mode 2 above) and the cleanup is to consolidate the OTA listing rather than create two canonical rooms.
- Reconcile attribute drift. For each canonical room, walk the OTA columns and confirm bed configuration, max occupancy, and accessibility flags match. If they don't, the canonical row's truth wins; update the OTA-side rooms to match. Most attribute drift comes from operator-side updates that propagated to one OTA but not the others.
- Allocate photos canonically. Photos belong to canonical rooms, not OTA listings. Once the canonical map is clean, every photo in your library should be tagged to one canonical room (or marked as a property-level shot like the lobby or exterior). Per-OTA photo selections then become "pick the best N photos for this canonical room and push them to OTA X." Most channel managers don't expose per-canonical-room photo tagging, so the workflow lives in your asset spreadsheet for now; OTALift's photo-allocation step also reads canonical rooms once they're defined.
- Re-audit quarterly. Room sets drift. Refurbishments add accessibility variants. Re-map at quarter-end and treat any new OTA-side room as needing a canonical assignment before it goes live.
The work above is one-time intensive (typically a half-day for a boutique) and then quarterly maintenance (typically an hour). The recurring cost is small once the canonical set is clean; the cost of skipping it shows up as silently miscompared parity reports and incomplete photo coverage.
Two scope notes the workflow assumes. If you run a channel manager (SiteMinder, Cloudbeds, Mews, RezGain), the canonical map needs to start there: the OTAs are downstream of the CM, and any per-OTA fixes you make in steps 3-5 will get overwritten on the next sync unless the CM's room model agrees. If you run more than one property, the canonical map is per-property in OTALift's data model today; cross-property photo strategy and pricing benchmarks layer on top, but the room map itself does not deduplicate across properties even when the rooms are physically similar.
Soft recommendations
The hard fix above gets the canonical map clean. Optional layers that compound:
- Pair the canonical map with a per-room conversion-rate spreadsheet. Most operators we looked at had no idea which canonical room converts best at which price. Adding the OTA-side conversion data, broken down by canonical room, surfaces the mix-shift opportunities.
- Treat the canonical room name as a copywriting problem, not a database one. The names that appear in your OTA listings are the names guests see in search results. "Garden King with Terrace" is more book-able than "Deluxe King Garden Terrace Room" because the modifier order matches how guests scan results.
- Document the canonical map as a living artifact. A simple Notion page or shared spreadsheet that staff can reference when answering "do we have a king that sleeps three?" prevents drift from individual updates.
Self-audit checklist
Run this on your own property without our product:
- I can name every distinct physical bookable room type at my property from memory.
- Each of my OTA-side rooms maps to exactly one of those physical types.
- My OTA-side room names use the same language guests use to describe the rooms in reviews.
- Bed configuration, max occupancy, and accessibility flags match across Booking, Expedia, and Google for the same physical room.
- Each photo in my library is tagged to a specific room (not "rooms in general").
- I have not added a new OTA-side room in the last 90 days without updating the canonical map.
- I can answer "what's the difference between my Deluxe King and Superior King" in one sentence (and the OTAs make the same distinction).
- My quarterly review includes a canonical-room audit, not just a rate audit.
- I know which canonical room converts at the highest rate, and which converts at the lowest.
- If I added an accessible variant of an existing room tomorrow, I know who would update the canonical map and on what timeline.
How OTALift surfaces this
OTALift generates canonical rooms when an operator triggers an Ideal Listing build for the property. The pipeline pulls every room from every OTA-side listing, computes nine deterministic pairwise similarity signals via roomSimilarityScorer, pre-clusters with a constrained Union-Find algorithm, then sends candidate clusters to a Gemini Flash model that confirms, splits, or merges them and produces a canonical name plus description. The output is a set of canonical Room rows attached to the property's ideal listing, with a RoomAlignment join table mapping each OTA-side room to its canonical parent with a confidence score and a matched/unmatched status.
What each measurement is doing under the hood
Six measurement decisions sit behind the canonical-room generation. Each is documented inline in the source for the next engineer.
- Nine signals, not one big LLM call. Each signal (name token-Jaccard, bed configuration, photo perceptual-hash overlap, max occupancy proximity, room type compatibility, amenity Jaccard, bathroom count, view tag, square meters) is cheap, deterministic, and individually weak. The composite holds up because no single signal dominates: a pair with identical names but mismatched bed configurations does not auto-merge; a pair with shared photos but different names still ranks highly. The deterministic layer is the cost gate before the LLM step.
- Weight ranking is operational, not calibrated. Name (0.25), beds (0.20), photos (0.15), occupancy/room type/amenity (0.10 each), bathroom (0.05), view/size (0.025 each). The ranking encodes the product team's belief about which signals are most diagnostic of "same physical room", not a calibrated optimum against ground-truth-labeled data. The lower weights for view and size reflect that those fields are frequently null or reported in different units across OTAs.
MERGE_THRESHOLD = 0.60is set conservatively. Below 0.60, a pair shouldn't be a merge candidate. The threshold leans toward under-merging (splitting rooms that should be one canonical) over over-merging (collapsing two distinct physical rooms), because over-merge is harder for the operator to detect. An operator looking at a canonical map sees four rooms when there should be three; they don't see two physical rooms hiding behind one canonical entry.NEUTRAL = 0.5for both-missing inputs. When neither room has a size recorded, the signal returns 0.5 rather than 0 (penalty) or 1 (free pass). Neutral keeps a missing signal from artificially pulling the composite up or down. Asymmetric "one-side missing" defaults (typically 0.2 or 0.3) penalize the case where one room has data and the other doesn't, which is weakly suggestive they aren't the same room.- Constrained Union-Find: same-listing pairs never cluster together. Structural truth: if Booking lists "Deluxe King" and "Superior King" as two separate rooms, they are by definition different physical rooms (the operator chose to list them separately). Without the constraint, the algorithm would merge them when names happen to be similar. This guarantees the LLM never sees a candidate group containing two rooms from the same OTA.
CLOSE_BED_TYPESpartial credit (0.7) for the Booking-vs-Expedia naming gap. Booking usesdouble(UK convention, equivalent to a US Full bed) for what Expedia and US-centric platforms callqueen. Treating these as a hard mismatch would split the same physical room into two canonical rooms across OTAs. 0.7 acknowledges the labeling disagreement without giving full credit, because there is a real bed-size difference between a UK Double and a US Queen, and the labeling disagreement is built into the platforms rather than being a translation problem.
What the LLM actually does (and doesn't)
The LLM step is asked to confirm/split/merge candidate groups, reassign unmatched rooms, and produce a canonical name + description per group. It is NOT asked to invent rooms (validated against the input UUID list; hallucinated UUIDs are dropped) or to override the same-listing constraint (preserved by the candidate-group structure). If more than 50 percent of input rooms come back missing or hallucinated, the pipeline throws and falls back to scoring-only clusters. The blended persisted confidence is 0.60 * scoring_avg + 0.40 * llm_confidence.
The Property Health signal
The Property Health report's RoomMatchingRule checks the canonical_rooms_defined signal and emits "Generate ideal listing first" (when no ideal listing exists yet) or "Re-run canonical room generation" (transient-crash recovery: ideal exists but has zero canonical rooms). Both route the operator to /ideal-listing for the property.
The signal is binary today (Room.count > 0 on the ideal listing → healthy). A property where the LLM merged everything into one garbage canonical room reads as healthy; the degraded tier is unreachable for this signal. The 2026-05-10 internal review recommended adding a quality-aware degraded tier based on unmatched-room ratio and mean alignment confidence, but landing it would flip the health status of every property whose canonical map is weak from healthy to degraded overnight. That's a meaningful product change deferred until there's an explicit operator-comms plan.
Recent product changes
A 2026-05-10 internal review of this surface surfaced three operator-facing gaps. Two were closed the same day; one remains deferred.
- Operator-editing UI: resolved by deletion (2026-05-10). The backend had been exposing dead
POST /:propertyId/alignmentsandDELETE /:propertyId/alignments/:alignmentIdendpoints (manualAlign/removeAlignment) that no frontend caller invoked. We deleted them. The honest reality today: regenerate is the only escape from a bad canonical map. An editor UI (rename a canonical room, drag-drop remap a source room, confirm/reject low-confidence merges) is on the backlog and will be built when operator demand makes it worth the frontend investment. - Trust calibration in the alignment table: landed (2026-05-11). Each canonical room in
RoomAlignmentTablenow surfaces a "N sources matched at avg X%" trust line, color-coded: green at avg ≥ 80%, amber at avg ≥ 60% (the backend'sMERGE_THRESHOLD), and red below 60%. The tooltip names the weakest source's confidence so the operator knows whether one OTA is dragging the mean. This is the non-binary trust signal the audit memo's Fix 5 called out; operators can now eyeball trust without reading per-alignment percentages cell-by-cell. - Manual-edit preservation: moot (2026-05-10). Was gated on the editor decision; with
manualAligngone, nomethod = 'manual'rows are written, so there's nothing to preserve across regenerate. Re-opens with the editor. - Quality-aware health signal: deferred. The
canonical_rooms_definedsignal is still binary (Room.count > 0on the ideal listing →healthy). The audit recommended adegradedtier driven by unmatched-room ratio and mean alignment confidence, but landing that flips the per-property health status of every property with a weak canonical map fromhealthytodegradedovernight, a meaningful product change that needs an operator-comms plan first.
Rate parity reports do not currently use the canonical room map. Parity comparisons are room-name-string-driven elsewhere in the codebase; bringing them onto the canonical layer is on the engineering backlog as a P1 follow-up. The downstream consumers that do use the canonical map today are the photo-recommendation strategies (per-canonical-room shot lists) and the cross-platform parity collector (per-platform room counts against the canonical benchmark).
Related articles
- The Ideal Hotel Listing Photo Set. The downstream consumer of canonical rooms: photo allocation depends on the room map being right.
- Booking.com as a Hotel Listing Venue. The Booking-specific room category structure that canonical rooms have to map back into.
- Expedia as a Hotel Listing Venue. Expedia's Visual Listing Framework and how its room hierarchy interacts with canonicalization.
- Pillar companion: How OTA Ranking Algorithms Actually Work. Why room-type accuracy is a search-filter precondition, not a cosmetic choice.
Sources and methodology
Authored by Anya Cortez · Reviewed by Tim Anastasiou · Last reviewed: 2026-05-10
Anya Cortez is OTALift's hospitality researcher and writes The Labs.
Footnotes
-
Booking.com Partner Hub, "Changing a room or unit name" (page stamp: "Updated 5 months ago"). Verbatim load-bearing claim: "Standard room and unit names help keep info clear and consistent for guests across our platform – and in all 43 languages we offer. Research shows that standard room and unit names also help generate more bookings." Plus the Room type / Room name / Custom name 3-field model that exactly mirrors Article 2's canonical-vs-OTA-vs-internal distinction. The originally-recalled URL (
/help/account/finance/setting-room-types) was a 404; this is the correct URL. https://partner.booking.com/en-us/help/rates-availability/room-settings/changing-room-or-unit-name ↩ ↩2 ↩3 ↩4 ↩5 -
Expedia Group Blog, "Decoding our algorithm" — Offer Strength factor #1 (Room availability and inventory) and factor #3 (Content completeness). Both factors directly depend on accurate canonical room mapping. The originally-recalled VLF post URL (
/resources/blog/visual-listing-framework) was a 404; the algorithm post covers the load-bearing claims. (The "5-level VLF hierarchy" specific to Expedia VLF was operator-detail color, not load-bearing — dropped.) https://partner.expediagroup.com/en-us/resources/blog/travel-marketplace-visibility-guide ↩ ↩2 -
Google Hotel Center, "room bundle" glossary entry. Verbatim definition: "A combination of a physical room type with different service packages. Room bundles let you define multiple room types for a single property, or combine an itinerary of a room with additional services and conditions of sale to your users beyond a standard price." Plus "Categories for lodging businesses" (https://support.google.com/hotelprices/answer/9970971) for the property-level lodging-type taxonomy that enforces classification independent of operator-chosen names. The originally-recalled URL was a 404; these are the correct URLs. https://support.google.com/hotelprices/answer/6336082 ↩ ↩2