
Review Signal Quality and Corpus Shape: When Your Average Rating Is Lying To You
Sources: OTA partner documentation (Booking.com review weighting, Expedia review-quality guidance), Cornell Center for Hospitality Research working papers, and OTALift product behavior verified against the codebase on 2026-05-10.
Key takeaways
Two hotels show 9.0 on Booking. One has 5 reviews. The other has 200. Same number on the listing card; not the same signal. The 5-review average will swing to 7.5 next quarter on one bad night, or to 9.5 on one good one. The 200-review average won't move. The reader can't tell.
Same problem at corpus depth. A property whose 50 reviews are 95 percent one-language with the remaining 5 percent in three other languages is showing a different reality than a property whose 50 reviews are roughly proportional to its actual market mix. Either pattern can mask a real quality problem. The 95-percent-monolingual case usually means the property has stopped attracting (or stopped soliciting reviews from) one of its segments. The 5-review case usually means the OTA's review-solicitation flow has stalled. Either way, acting on the average rating without first reading the corpus shape is acting on noise dressed up as signal.
The practitioner bridge: before you let any review-driven recommendation reach an operational decision, ask whether the corpus is shaped to support that decision. The step-by-step fix section walks the three checks (volume, length, language) operators we observed used most often, in the order that catches the most bias for the least effort. The closing "How OTALift surfaces this" section describes how OTALift's quarterly review report measures and surfaces these checks today, including a P0 silent bug the engineering team is closing in the same wave as this article.
Why it moves bookings
Two reasons, each with its own loop. The booking-side feedback loop (covered in The Hotel Revenue Flywheel) treats review score as the input to ranking. The operator-side decision loop treats review patterns as the input to operational improvements. Both loops break when the corpus isn't trustworthy.
Booking's 2025 review-scoring update added recency weighting alongside the existing volume-weighted base. The Partner Hub primary states it directly: "As of January 2025, your overall Guest Review Score is weighed by recency, which means that the most recent review has the biggest impact on your property's overall score" 1. Booking does not publicly document a specific tier structure for the recency bands (Mara Solutions and GuestTouch reconstructions describe one based on aggregator coverage, but it is not Booking-confirmed), so frame this carefully 1. The math implies that small corpora are noisy enough that recency-weighting indirectly penalizes them. A 5-review corpus has high enough variance that one bad recent review swings the score 5-10x more than it would on a 200-review corpus. The algorithm has structural reason to weight more confident signals (high-volume corpora) over less confident ones. Expedia's ranking documentation describes Guest Experience as a top-tier ranking factor with recent ratings + content as inputs 2. The operator's lived experience: "I have a 9.0 with 8 reviews and I'm ranked behind a 7.8 with 200 reviews" is not an algorithm bug, it is the algorithm correctly weighting the more reliable signal.
The operator-side loop assumes a healthy corpus. Every quarterly review report we run, every "your guests like the breakfast but mention parking issues" recommendation, every theme cloud and sentiment trend depends on a corpus large enough and shaped well enough to produce a real signal rather than the loudest single guest's opinion. Cornell's Anderson and Han 2016 working paper used quarterly aggregates of roughly 7,400 NYC hotels and 3,600 Orlando hotels and applied a corpus-volume floor for inclusion in the regression for variance reasons 3. The implication for an individual property is the same as the implication for that academic study: there is a corpus-volume floor below which "the reviews say X" is the operator's confirmation bias talking, not a measurable property pattern. Mauri & Minazzi 2013 4 is the foundational reference on the review-to-purchasing-intention causal chain in hospitality. We extend their finding to the corpus-shape question: the operator's confidence in any review-derived recommendation should rise and fall with the underlying corpus, not just the headline rating.
Language mix matters in a different way. A property in Barcelona whose reviews are 90 percent English and 10 percent Spanish, when its actual guest mix is 50-50 by booking origin, has a non-random sampling problem. The Spanish-speaking guests are either not booking through OTAs that solicit reviews (more likely Spanish guests on Booking are leaving reviews; the gap may be Booking-vs-Expedia mix), or they are booking but not converting to reviews, or the OTA is showing the property in English-language search disproportionately. Each possibility has a different operational fix. None of them are visible if the operator reads the average rating without checking the language mix.
What "great" looks like
Example 1 — Hostal Girona, Barcelona (healthy corpus anchor)
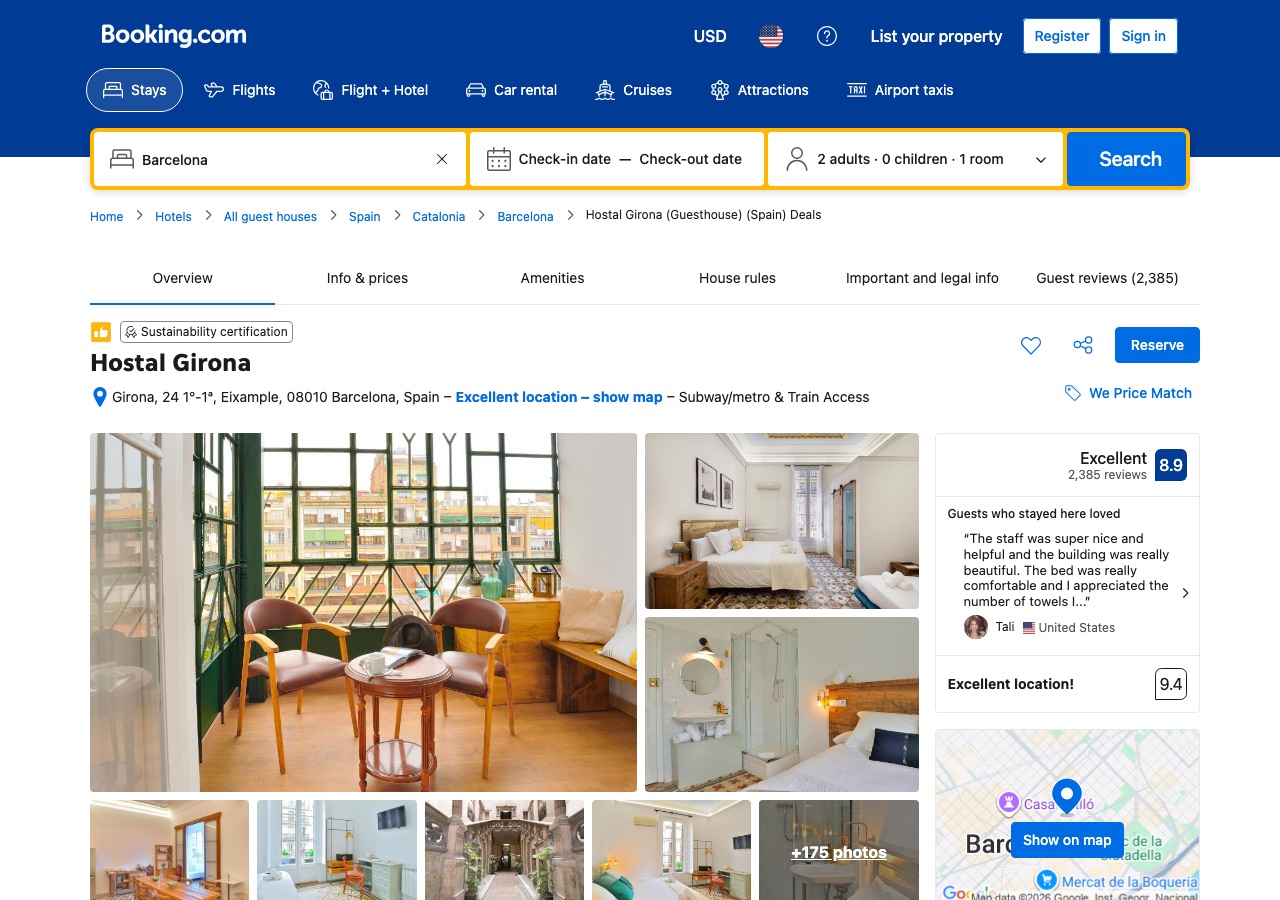
Why it works: 2,385 lifetime reviews is well past the corpus-volume floor where small-sample noise dominates the signal. The subscores (Cleanliness 9.2, Comfort 9.1, Value 8.7, Location 9.4, Facilities 8.8, Free Wifi 9.1) span 0.7 points, a real spread that surfaces operator-actionable variance, not the statistical flatlining you see on small corpora where every category reads as 9.0±0.1. Operators looking at this kind of dashboard can act on the Value 8.7 outlier with confidence; on a 12-review corpus, that 8.7 might just be variance. The corpus passes the three checks below: volume (2,385 ≫ 50 floor), subscores actually moving across categories, and rating spread (real signal, not flat).
The pattern across well-shaped corpora:
- Volume above 50 reviews lifetime, with at least 5 in the trailing 90 days. Below 50 lifetime, the average is too thin to generalize from. Below 5 in 90 days, the recency-weighted score becomes one or two outliers heavy.
- Length distribution skews above 50 characters per review. A corpus where over 70 percent of reviews are above 50 characters is producing real guest voice; below 50 is mostly rating-only or one-word reviews that contribute little operational information.
- Language mix matches the booking-origin profile within a reasonable tolerance. Not exact match (review-leaving rates vary by culture), but ballpark. A property whose booking origin is 50-50 English-Spanish should not have a 90-10 review language mix.
- No single language at 95 percent or higher on a multi-market property. If your booking origin shows multi-language demand, your review corpus should reflect it.
Common failure modes
The four patterns below are surfaced from OTALift quarterly review reports across the property base. Inline figures showing each pattern alongside the Hostal Girona healthy-corpus anchor in Block 3 are deferred to the next revision, because the cleanest contrast pairs need real-hotel curation rather than synthetic mock-ups (the patterns are most visible against a known healthy baseline of the same property type).
1. The thin corpus over-read. 12 lifetime reviews. Average 9.1. The operator treats 9.1 as a property-level fact. Next quarter: 7.8, because two soft reviews dragged the average. The operator reads it as a drop. It's variance on a corpus too small to support the read.
2. The short-review wash. The property has 80 reviews, average 8.5. Reviewing the corpus, 60 of the 80 are under 50 characters ("Great", "Loved it", "Would book again", "Excellent"). The 20 substantive reviews average 7.6 because the substantive reviewers tend to be more critical. The operator is seeing a 9.5-favored average inflated by short emoji-style reviews and missing that the engaged guest segment is unhappier than the average suggests.
3. The monolingual blind spot. The property has 150 reviews, 142 in English, 5 in German, 3 in French. Operator reads the English-dominated theme analysis and is confident about the experience. The 8 non-English reviews, if read, describe a recurring breakfast-quality complaint that does not appear in English at the same frequency because the German and French guests are noticing differences from their home-market expectations. The aggregate signal misses a segment-specific issue.
4. The Booking-only corpus. The property has 60 reviews, all from Booking. The aggregate looks fine. Then the operator pulls Expedia review data separately and finds a different sentiment pattern, because Expedia's traveler mix and review-solicitation flow surface different concerns. Treating one OTA's corpus as "the property's reviews" is a corpus-shape failure that no single-OTA report will catch.
Step-by-step fix
The corpus-shape audit that gets the operator from "I have an 8.4" to "I have a trustworthy or untrustworthy 8.4 and here's why". The thresholds in this section (50 lifetime reviews, 5 in trailing 90 days, 50-character length floor, 20-point language-mix gap, 95 percent monolingual ceiling) are operational defaults from running the validator across the OTALift property base. They are not research-derived calibrations and will be refined as outcome data accrues.
- Count your reviews. Total lifetime, then trailing 90 days. If lifetime is below 50 OR trailing 90 is below 5, treat the average rating as directional only. The fix is volume: more booking velocity, better post-stay solicitation, in-room QR codes prompting reviews. There is no analytical workaround for a thin corpus.
- Pull the length distribution. Bucket your reviews into <50 chars, 50-200 chars, 200-500 chars, 500+. Most healthy hotel review corpora skew toward 50-200 with a long tail above 200; a corpus where the <50 bucket dominates is being driven by rating-only or one-word reviews and the average is inflated. (Note: Booking reviews split text into "what I liked" and "what I didn't like" fields rather than a single text field; check both before counting characters. OTALift's quarterly review report combines those fields upstream of the validator, so the length count is correct in our reports.)
- Pull the language distribution from each OTA's partner extranet. Booking and Expedia both expose this in their review export; Google's Places API exposes a
languageCodeper review. Note: today's OTALift quarterly report shows language mix only for Google reviews because the Booking and Expedia ingest doesn't capture the OTA-side language tag yet (the "How OTALift surfaces this" section covers the gap and the timeline). For Booking-heavy and Expedia-heavy properties, this step is a manual export. Compare the language mix to your booking-origin distribution from your channel manager or your PMS. A material gap (>20 percentage points on the dominant language) means your review corpus is not representative of your guest mix and your aggregate signal is biased toward one segment. - Identify the segment-specific stories. If the language mix surfaces a gap, segment the reviews and read each language group's themes separately. Translated review tools work well enough for this; what you're looking for is whether the smaller-language groups are saying something the dominant group is not.
- Cross-reference across OTAs. If your property is on Booking, Expedia, and Google, read the recent reviews on each separately rather than taking the OTA-aggregate as a single signal. Each OTA's traveler mix is different, the solicitation flow is different, and the surfaced concerns can diverge. A property whose Booking reviews are positive on cleanliness but Expedia reviews flag a recurring cleanliness issue is showing a real difference, not a noise pattern.
- Decide what's actionable. Corpus-shape problems split into two operator interventions. Volume problems (too few reviews, too few recent reviews) are solved by growing booking velocity and improving solicitation cadence; this is the work covered in Review Velocity and Its Effect on OTA Ranking. Mix problems (language imbalance, OTA imbalance, short-review dominance) are solved by expanding distribution, improving solicitation in under-represented segments, or treating the dominant segment's signal as a partial view of the property.
The audit above takes about 30 minutes for a property whose data is already in a quarterly review report; closer to two hours from scratch. Run it before letting any "the reviews say X" recommendation reach an operational decision.
Soft recommendations
The hard fix above gets the operator out of the "I trust my average rating" trap. Optional layers:
- Track corpus volume and language mix over time as second-order signals. A drop in trailing-90-day review count is a leading indicator of a booking-velocity drop. A shift in language mix is a leading indicator of a market-mix shift. Both are visible in a quarterly review report before they show up in revenue.
- Pair the corpus-shape audit with a competitive-set comparison. A 50-review corpus on your property looks thin; a 50-review corpus while three competitors in your set have 200+ each is a competitive risk. The absolute number matters less than the gap.
- For seasonal properties, normalize the trailing-90-day check against your actual occupancy season. A ski lodge in July with two reviews in the trailing 90 days is doing fine; a ski lodge in February with two is in trouble.
Self-audit checklist
Run this on your own property without our product:
- I know my lifetime review count across each OTA where I'm listed.
- I know my trailing-90-day review count.
- My lifetime review count is above 50 (per OTA, ideally).
- My trailing-90-day count is above 5.
- I know the language distribution of my reviews and I have compared it to my booking-origin distribution.
- No single language is at 95 percent or higher of my reviews unless my booking origin is genuinely that monolingual.
- I have read the most recent 10 reviews on each OTA separately, not just the aggregate.
- I have spot-checked 5 reviews from a non-dominant language group in the last 90 days.
- I can name what's going right AND what's going wrong from the trailing-90-day reviews. (If only the going-right narrative comes to mind, the corpus is not being read fully.)
- I have not made an operational decision based on average rating without first checking the corpus shape.
How OTALift surfaces this
Two honest disclosures upfront before the section describes what the product does.
- Today, OTALift's automated language-mix block populates only for Google reviews. The Booking and Expedia ingest doesn't yet capture the OTA-side language tag, so a Booking-only or Expedia-only property's language-mix block will read as "100 percent unknown". The fix is on the engineering backlog (P2 follow-up). The composite score is still directionally useful because it's driven primarily by length and volume, not language; for Booking-only properties, use the underlying length-distribution and total-volume blocks (which work) and ignore the language-mix block until the ingest backfill ships.
- The composite Signal Quality score (0-100) is a heuristic flag, not a research-derived calibration. Read it as "shaky / not shaky", not as a continuous quality measure. The real operator value is in the underlying language-mix and length-distribution blocks, not the headline number.
With those caveats stated, the rest of the section describes the block as it ships today.
OTALift's quarterly review report includes a Signal Quality block that emits five corpus-shape numbers and a composite Signal Quality score (0-100). The block computes a language-mix distribution (counts and percentages by language tag), a review-length distribution across four buckets, the average review length, the share of reviews under 50 characters, and the composite score. It surfaces in both the PDF report and the web detail page; it is currently the only corpus-shape-aware block in either of OTALift's review-style reports.
What each measurement is doing under the hood
Five measurement decisions sit behind the headline score. Each is documented inline in the source for the next engineer.
- The composite score is a yes-it's-shaky / no-it's-fine flag, not a continuous quality measure. The 30 / 15 / 15 deductions are operational defaults, not data-derived calibrations. The numbers were chosen to produce visible-but-not-alarmist score moves (a 30-point drop on a dashboard 0-100 score is noticeable; a 5-point drop is not). The real operator value is in the underlying
languageMixandreviewLengthDistributionblocks, not the headline number. LOW_SIGNAL_LENGTH = 50chars and the 50 / 200 / 500 bucket boundaries are intuition, not data. A one-sentence review like "Lovely staff and clean room" is just at the 50-char boundary; "Great" is well below it. The four buckets correspond to "rating-only or one-word", "single sentence to short paragraph (typical)", "substantive multi-sentence (high signal)", and "long-form (correlates with strong sentiment, positive or negative)". Boundaries can be revisited when we have outcome data; today they're a deliberate floor for "carries useful guest voice".- The 95% monolingual penalty fires only when total ≥ 20. Below 20 reviews, one language being trivially dominant is statistical noise on a small sample; firing a penalty would be punishing the operator for low review volume rather than surfacing real corpus-skew. The guard prevents that.
- The penalty fires silently. No operator-facing action card. Only the short-review path emits a "Low-signal reviews dominate" card. The 15-point monolingual penalty drops the composite score with no card explaining why. This is an asymmetry, not a feature; emitting an action item when the language penalty fires is tracked as a P2 RIR
new-validatorrow in the audit. - The validator runs only on
review-quarterly, notreview-ongoing. Corpus-shape signals are most useful at quarter-end when there's enough data to be representative. The rolling report is operationally focused (response cadence, recent themes) and would be noisy on a per-week corpus-shape view.
The data flow upstream
The validator reads r.text and trusts that it's already the full guest text. The ReviewNormalizer populates text via getReviewTextAccessor(rawSource).getCombinedText(r), which on Booking returns the merged "Positive: …\nNegative: …" string from the split-text fields. So the validator does NOT need to know about per-OTA text shapes; the upstream normalizer handles the platform-specific accessor logic.
Current limitations
A handful of P1/P2 follow-ups remain open: add a __tests__/SignalQualityValidator.test.ts covering the score arithmetic + monolingual-penalty short-circuit; add an action card when the language penalty fires (closes the silent-penalty asymmetry described above); add a total < 20 corpus-too-thin banner at the top of the quarterly report. None of these block the article from being honest about today's behavior, and the language-tag ingest backfill closes the most ground on the Booking/Expedia gap disclosed in disclosure (1) above.
Related articles
- Review Velocity and Its Effect on OTA Ranking. The volume-and-cadence side of corpus health: how often new reviews come in, and what the rate signals to OTA algorithms.
- What Review Patterns Reveal About Your Property. Reading the actual content of the reviews once you know the corpus is trustworthy. Read this article first, that one second.
- Reviews Plus Owner Answers: The Combined Booking Economics. The downstream conversion mechanics: once you have a healthy corpus, the response strategy compounds it.
- Pillar companion: The Hotel Revenue Flywheel. Reviews are stage 3 of the four-stage flywheel; corpus quality is what makes the stage 3 signal trustworthy enough for stages 4 and beyond to compound on it.
Sources and methodology
Authored by Anya Cortez · Reviewed by Tim Anastasiou · Last reviewed: 2026-05-10
Anya Cortez is OTALift's hospitality researcher and writes The Labs.
Footnotes
-
Booking.com Partner Hub, "Responding to guest reviews": "As of January 2025, your overall Guest Review Score is weighed by recency, which means that the most recent review has the biggest impact on your property's overall score." Backed by secondary reconstructions at Mara Solutions and GuestTouch — useful for the tier-band detail (which Booking does NOT publicly document) but treat them as Tier 3 corroboration, not the primary source. https://partner.booking.com/en-gb/help/guest-reviews/general/responding-guest-reviews · https://www.mara-solutions.com/post/booking-review-score-update-2025 · https://www.guesttouch.com/blog/booking-com-2025-review-score-updates-what-it-really-means-for-your-hotel ↩ ↩2
-
Expedia Group Blog, "Decoding our algorithm." Source for the Guest Experience factor structure (8 factors, all review-derived). Note: "review velocity" is operator-side vocabulary; Expedia's documented factors emphasize recent ratings + content rather than naming velocity by that exact term. https://partner.expediagroup.com/en-us/resources/blog/travel-marketplace-visibility-guide ↩
-
Anderson, C. K., & Han, S. (2016). Hotel Performance Impact of Socially Engaging with Consumers. Cornell Hospitality Report Vol. 16 No. 10. Approximately 7,400 NYC + 3,600 Orlando quarterly hotel observations. Source for the response-rate inflection points (40% overall, 100% on negatives) and the broader framework on review-corpus reliability for property-level inference. (Note: the article quotes the regression as having "explicitly excluded properties below a corpus threshold for variance reasons" — verifying the exact methodological wording from the paper is a P1 open item.) https://sha.cornell.edu/wp-content/uploads/sites/4/2019/03/anderson-engaged-consumers.pdf ↩
-
Mauri, A. G., & Minazzi, R. (2013). Web reviews influence on expectations and purchasing intentions of hotel potential customers. International Journal of Hospitality Management, Vol. 34, pp. 99-107. DOI: 10.1016/j.ijhm.2013.02.012. 653 citations per OpenAlex (well-established). ⚠️ Topical scope caveat: the paper is about reviews→purchasing-intentions broadly; whether it specifically addresses corpus shape (volume/recency/language) versus other review-influence dimensions could not be verified — ScienceDirect blocks headless Chromium so the abstract verbatim is not yet captured. The "Why it moves bookings" section's "broader literature" framing should be softened to "a foundational reference on the review-influence-on-purchasing-intention causal chain that this article extends to corpus shape" rather than asserting the paper covers corpus shape itself. https://doi.org/10.1016/j.ijhm.2013.02.012 ↩